mirror of
https://github.com/THU-MIG/yolov10.git
synced 2025-12-17 00:16:11 +08:00
ultralytics 8.0.228 add training time argument (#7054)
Signed-off-by: Glenn Jocher <glenn.jocher@ultralytics.com> Co-authored-by: pre-commit-ci[bot] <66853113+pre-commit-ci[bot]@users.noreply.github.com>
This commit is contained in:
parent
b206b68ac6
commit
6cbe736bfd
@ -8,8 +8,9 @@ keywords: Ultralytics, YOLOv8, Instance Segmentation, Object Detection, Object T
|
|||||||
|
|
||||||
## What is Instance Segmentation?
|
## What is Instance Segmentation?
|
||||||
|
|
||||||
[Ultralytics YOLOv8](https://github.com/ultralytics/ultralytics/) Instance segmentation involves identifying and outlining individual objects in an image, providing a detailed understanding of spatial distribution. Unlike semantic segmentation, it uniquely labels and precisely delineates each object, crucial for tasks like object detection and medical imaging.
|
[Ultralytics YOLOv8](https://github.com/ultralytics/ultralytics/) instance segmentation involves identifying and outlining individual objects in an image, providing a detailed understanding of spatial distribution. Unlike semantic segmentation, it uniquely labels and precisely delineates each object, crucial for tasks like object detection and medical imaging.
|
||||||
Two Types of instance segmentation by Ultralytics YOLOv8.
|
|
||||||
|
There are two types of instance segmentation tracking available in the Ultralytics package:
|
||||||
|
|
||||||
- **Instance Segmentation with Class Objects:** Each class object is assigned a unique color for clear visual separation.
|
- **Instance Segmentation with Class Objects:** Each class object is assigned a unique color for clear visual separation.
|
||||||
|
|
||||||
@ -22,7 +23,6 @@ Two Types of instance segmentation by Ultralytics YOLOv8.
|
|||||||
|  |  |
|
|  |  |
|
||||||
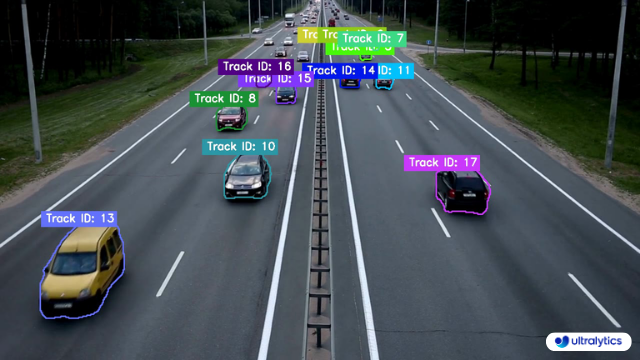
| Ultralytics Instance Segmentation 😍 | Ultralytics Instance Segmentation with Object Tracking 🔥 |
|
| Ultralytics Instance Segmentation 😍 | Ultralytics Instance Segmentation with Object Tracking 🔥 |
|
||||||
|
|
||||||
|
|
||||||
!!! Example "Instance Segmentation and Tracking"
|
!!! Example "Instance Segmentation and Tracking"
|
||||||
|
|
||||||
=== "Instance Segmentation"
|
=== "Instance Segmentation"
|
||||||
|
|||||||
@ -22,12 +22,12 @@ keywords: Ultralytics, YOLOv8, Object Detection, Object Tracking, IDetection, Vi
|
|||||||
</p>
|
</p>
|
||||||
|
|
||||||
## Samples
|
## Samples
|
||||||
|
|
||||||
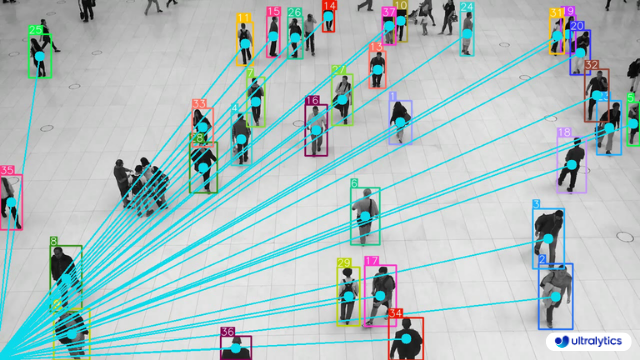
| VisionEye View | VisionEye View With Object Tracking |
|
| VisionEye View | VisionEye View With Object Tracking |
|
||||||
|:------------------------------------------------------------------------------------------------------------------------------------------------------------:|:---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------:|
|
|:------------------------------------------------------------------------------------------------------------------------------------------------------------:|:---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------:|
|
||||||
|  |  |
|
|  |  |
|
||||||
| VisionEye View Object Mapping using Ultralytics YOLOv8 | VisionEye View Object Mapping with Object Tracking using Ultralytics YOLOv8 |
|
| VisionEye View Object Mapping using Ultralytics YOLOv8 | VisionEye View Object Mapping with Object Tracking using Ultralytics YOLOv8 |
|
||||||
|
|
||||||
|
|
||||||
!!! Example "VisionEye Object Mapping using YOLOv8"
|
!!! Example "VisionEye Object Mapping using YOLOv8"
|
||||||
|
|
||||||
=== "VisionEye Object Mapping"
|
=== "VisionEye Object Mapping"
|
||||||
|
|||||||
@ -180,6 +180,7 @@ Training settings for YOLO models refer to the various hyperparameters and confi
|
|||||||
| `model` | `None` | path to model file, i.e. yolov8n.pt, yolov8n.yaml |
|
| `model` | `None` | path to model file, i.e. yolov8n.pt, yolov8n.yaml |
|
||||||
| `data` | `None` | path to data file, i.e. coco128.yaml |
|
| `data` | `None` | path to data file, i.e. coco128.yaml |
|
||||||
| `epochs` | `100` | number of epochs to train for |
|
| `epochs` | `100` | number of epochs to train for |
|
||||||
|
| `time` | `None` | number of hours to train for, overrides epochs if supplied |
|
||||||
| `patience` | `50` | epochs to wait for no observable improvement for early stopping of training |
|
| `patience` | `50` | epochs to wait for no observable improvement for early stopping of training |
|
||||||
| `batch` | `16` | number of images per batch (-1 for AutoBatch) |
|
| `batch` | `16` | number of images per batch (-1 for AutoBatch) |
|
||||||
| `imgsz` | `640` | size of input images as integer |
|
| `imgsz` | `640` | size of input images as integer |
|
||||||
|
|||||||
@ -88,6 +88,7 @@ The training settings for YOLO models encompass various hyperparameters and conf
|
|||||||
| `model` | `None` | path to model file, i.e. yolov8n.pt, yolov8n.yaml |
|
| `model` | `None` | path to model file, i.e. yolov8n.pt, yolov8n.yaml |
|
||||||
| `data` | `None` | path to data file, i.e. coco128.yaml |
|
| `data` | `None` | path to data file, i.e. coco128.yaml |
|
||||||
| `epochs` | `100` | number of epochs to train for |
|
| `epochs` | `100` | number of epochs to train for |
|
||||||
|
| `time` | `None` | number of hours to train for, overrides epochs if supplied |
|
||||||
| `patience` | `50` | epochs to wait for no observable improvement for early stopping of training |
|
| `patience` | `50` | epochs to wait for no observable improvement for early stopping of training |
|
||||||
| `batch` | `16` | number of images per batch (-1 for AutoBatch) |
|
| `batch` | `16` | number of images per batch (-1 for AutoBatch) |
|
||||||
| `imgsz` | `640` | size of input images as integer |
|
| `imgsz` | `640` | size of input images as integer |
|
||||||
|
|||||||
@ -61,6 +61,7 @@ def test_autobatch():
|
|||||||
check_train_batch_size(YOLO(MODEL).model.cuda(), imgsz=128, amp=True)
|
check_train_batch_size(YOLO(MODEL).model.cuda(), imgsz=128, amp=True)
|
||||||
|
|
||||||
|
|
||||||
|
@pytest.mark.slow
|
||||||
@pytest.mark.skipif(not CUDA_IS_AVAILABLE, reason='CUDA is not available')
|
@pytest.mark.skipif(not CUDA_IS_AVAILABLE, reason='CUDA is not available')
|
||||||
def test_utils_benchmarks():
|
def test_utils_benchmarks():
|
||||||
"""Profile YOLO models for performance benchmarks."""
|
"""Profile YOLO models for performance benchmarks."""
|
||||||
|
|||||||
@ -1,6 +1,6 @@
|
|||||||
# Ultralytics YOLO 🚀, AGPL-3.0 license
|
# Ultralytics YOLO 🚀, AGPL-3.0 license
|
||||||
|
|
||||||
__version__ = '8.0.227'
|
__version__ = '8.0.228'
|
||||||
|
|
||||||
from ultralytics.models import RTDETR, SAM, YOLO
|
from ultralytics.models import RTDETR, SAM, YOLO
|
||||||
from ultralytics.models.fastsam import FastSAM
|
from ultralytics.models.fastsam import FastSAM
|
||||||
|
|||||||
@ -63,7 +63,7 @@ CLI_HELP_MSG = \
|
|||||||
"""
|
"""
|
||||||
|
|
||||||
# Define keys for arg type checks
|
# Define keys for arg type checks
|
||||||
CFG_FLOAT_KEYS = 'warmup_epochs', 'box', 'cls', 'dfl', 'degrees', 'shear'
|
CFG_FLOAT_KEYS = 'warmup_epochs', 'box', 'cls', 'dfl', 'degrees', 'shear', 'time'
|
||||||
CFG_FRACTION_KEYS = ('dropout', 'iou', 'lr0', 'lrf', 'momentum', 'weight_decay', 'warmup_momentum', 'warmup_bias_lr',
|
CFG_FRACTION_KEYS = ('dropout', 'iou', 'lr0', 'lrf', 'momentum', 'weight_decay', 'warmup_momentum', 'warmup_bias_lr',
|
||||||
'label_smoothing', 'hsv_h', 'hsv_s', 'hsv_v', 'translate', 'scale', 'perspective', 'flipud',
|
'label_smoothing', 'hsv_h', 'hsv_s', 'hsv_v', 'translate', 'scale', 'perspective', 'flipud',
|
||||||
'fliplr', 'mosaic', 'mixup', 'copy_paste', 'conf', 'iou', 'fraction') # fraction floats 0.0 - 1.0
|
'fliplr', 'mosaic', 'mixup', 'copy_paste', 'conf', 'iou', 'fraction') # fraction floats 0.0 - 1.0
|
||||||
|
|||||||
@ -8,6 +8,7 @@ mode: train # (str) YOLO mode, i.e. train, val, predict, export, track, benchma
|
|||||||
model: # (str, optional) path to model file, i.e. yolov8n.pt, yolov8n.yaml
|
model: # (str, optional) path to model file, i.e. yolov8n.pt, yolov8n.yaml
|
||||||
data: # (str, optional) path to data file, i.e. coco128.yaml
|
data: # (str, optional) path to data file, i.e. coco128.yaml
|
||||||
epochs: 100 # (int) number of epochs to train for
|
epochs: 100 # (int) number of epochs to train for
|
||||||
|
time: # (float, optional) number of hours to train for, overrides epochs if supplied
|
||||||
patience: 50 # (int) epochs to wait for no observable improvement for early stopping of training
|
patience: 50 # (int) epochs to wait for no observable improvement for early stopping of training
|
||||||
batch: 16 # (int) number of images per batch (-1 for AutoBatch)
|
batch: 16 # (int) number of images per batch (-1 for AutoBatch)
|
||||||
imgsz: 640 # (int | list) input images size as int for train and val modes, or list[w,h] for predict and export modes
|
imgsz: 640 # (int | list) input images size as int for train and val modes, or list[w,h] for predict and export modes
|
||||||
|
|||||||
@ -100,7 +100,7 @@ def build_dataloader(dataset, batch, workers, shuffle=True, rank=-1):
|
|||||||
"""Return an InfiniteDataLoader or DataLoader for training or validation set."""
|
"""Return an InfiniteDataLoader or DataLoader for training or validation set."""
|
||||||
batch = min(batch, len(dataset))
|
batch = min(batch, len(dataset))
|
||||||
nd = torch.cuda.device_count() # number of CUDA devices
|
nd = torch.cuda.device_count() # number of CUDA devices
|
||||||
nw = min([os.cpu_count() // max(nd, 1), batch if batch > 1 else 0, workers]) # number of workers
|
nw = min([os.cpu_count() // max(nd, 1), batch, workers]) # number of workers
|
||||||
sampler = None if rank == -1 else distributed.DistributedSampler(dataset, shuffle=shuffle)
|
sampler = None if rank == -1 else distributed.DistributedSampler(dataset, shuffle=shuffle)
|
||||||
generator = torch.Generator()
|
generator = torch.Generator()
|
||||||
generator.manual_seed(6148914691236517205 + RANK)
|
generator.manual_seed(6148914691236517205 + RANK)
|
||||||
|
|||||||
@ -189,6 +189,14 @@ class BaseTrainer:
|
|||||||
else:
|
else:
|
||||||
self._do_train(world_size)
|
self._do_train(world_size)
|
||||||
|
|
||||||
|
def _setup_scheduler(self):
|
||||||
|
"""Initialize training learning rate scheduler."""
|
||||||
|
if self.args.cos_lr:
|
||||||
|
self.lf = one_cycle(1, self.args.lrf, self.epochs) # cosine 1->hyp['lrf']
|
||||||
|
else:
|
||||||
|
self.lf = lambda x: max(1 - x / self.epochs, 0) * (1.0 - self.args.lrf) + self.args.lrf # linear
|
||||||
|
self.scheduler = optim.lr_scheduler.LambdaLR(self.optimizer, lr_lambda=self.lf)
|
||||||
|
|
||||||
def _setup_ddp(self, world_size):
|
def _setup_ddp(self, world_size):
|
||||||
"""Initializes and sets the DistributedDataParallel parameters for training."""
|
"""Initializes and sets the DistributedDataParallel parameters for training."""
|
||||||
torch.cuda.set_device(RANK)
|
torch.cuda.set_device(RANK)
|
||||||
@ -269,11 +277,7 @@ class BaseTrainer:
|
|||||||
decay=weight_decay,
|
decay=weight_decay,
|
||||||
iterations=iterations)
|
iterations=iterations)
|
||||||
# Scheduler
|
# Scheduler
|
||||||
if self.args.cos_lr:
|
self._setup_scheduler()
|
||||||
self.lf = one_cycle(1, self.args.lrf, self.epochs) # cosine 1->hyp['lrf']
|
|
||||||
else:
|
|
||||||
self.lf = lambda x: (1 - x / self.epochs) * (1.0 - self.args.lrf) + self.args.lrf # linear
|
|
||||||
self.scheduler = optim.lr_scheduler.LambdaLR(self.optimizer, lr_lambda=self.lf)
|
|
||||||
self.stopper, self.stop = EarlyStopping(patience=self.args.patience), False
|
self.stopper, self.stop = EarlyStopping(patience=self.args.patience), False
|
||||||
self.resume_training(ckpt)
|
self.resume_training(ckpt)
|
||||||
self.scheduler.last_epoch = self.start_epoch - 1 # do not move
|
self.scheduler.last_epoch = self.start_epoch - 1 # do not move
|
||||||
@ -285,17 +289,18 @@ class BaseTrainer:
|
|||||||
self._setup_ddp(world_size)
|
self._setup_ddp(world_size)
|
||||||
self._setup_train(world_size)
|
self._setup_train(world_size)
|
||||||
|
|
||||||
self.epoch_time = None
|
|
||||||
self.epoch_time_start = time.time()
|
|
||||||
self.train_time_start = time.time()
|
|
||||||
nb = len(self.train_loader) # number of batches
|
nb = len(self.train_loader) # number of batches
|
||||||
nw = max(round(self.args.warmup_epochs * nb), 100) if self.args.warmup_epochs > 0 else -1 # warmup iterations
|
nw = max(round(self.args.warmup_epochs * nb), 100) if self.args.warmup_epochs > 0 else -1 # warmup iterations
|
||||||
last_opt_step = -1
|
last_opt_step = -1
|
||||||
|
self.epoch_time = None
|
||||||
|
self.epoch_time_start = time.time()
|
||||||
|
self.train_time_start = time.time()
|
||||||
self.run_callbacks('on_train_start')
|
self.run_callbacks('on_train_start')
|
||||||
LOGGER.info(f'Image sizes {self.args.imgsz} train, {self.args.imgsz} val\n'
|
LOGGER.info(f'Image sizes {self.args.imgsz} train, {self.args.imgsz} val\n'
|
||||||
f'Using {self.train_loader.num_workers * (world_size or 1)} dataloader workers\n'
|
f'Using {self.train_loader.num_workers * (world_size or 1)} dataloader workers\n'
|
||||||
f"Logging results to {colorstr('bold', self.save_dir)}\n"
|
f"Logging results to {colorstr('bold', self.save_dir)}\n"
|
||||||
f'Starting training for {self.epochs} epochs...')
|
f'Starting training for '
|
||||||
|
f'{self.args.time} hours...' if self.args.time else f'{self.epochs} epochs...')
|
||||||
if self.args.close_mosaic:
|
if self.args.close_mosaic:
|
||||||
base_idx = (self.epochs - self.args.close_mosaic) * nb
|
base_idx = (self.epochs - self.args.close_mosaic) * nb
|
||||||
self.plot_idx.extend([base_idx, base_idx + 1, base_idx + 2])
|
self.plot_idx.extend([base_idx, base_idx + 1, base_idx + 2])
|
||||||
@ -323,7 +328,7 @@ class BaseTrainer:
|
|||||||
ni = i + nb * epoch
|
ni = i + nb * epoch
|
||||||
if ni <= nw:
|
if ni <= nw:
|
||||||
xi = [0, nw] # x interp
|
xi = [0, nw] # x interp
|
||||||
self.accumulate = max(1, np.interp(ni, xi, [1, self.args.nbs / self.batch_size]).round())
|
self.accumulate = max(1, int(np.interp(ni, xi, [1, self.args.nbs / self.batch_size]).round()))
|
||||||
for j, x in enumerate(self.optimizer.param_groups):
|
for j, x in enumerate(self.optimizer.param_groups):
|
||||||
# Bias lr falls from 0.1 to lr0, all other lrs rise from 0.0 to lr0
|
# Bias lr falls from 0.1 to lr0, all other lrs rise from 0.0 to lr0
|
||||||
x['lr'] = np.interp(
|
x['lr'] = np.interp(
|
||||||
@ -348,6 +353,16 @@ class BaseTrainer:
|
|||||||
self.optimizer_step()
|
self.optimizer_step()
|
||||||
last_opt_step = ni
|
last_opt_step = ni
|
||||||
|
|
||||||
|
# Timed stopping
|
||||||
|
if self.args.time:
|
||||||
|
self.stop = (time.time() - self.train_time_start) > (self.args.time * 3600)
|
||||||
|
if RANK != -1: # if DDP training
|
||||||
|
broadcast_list = [self.stop if RANK == 0 else None]
|
||||||
|
dist.broadcast_object_list(broadcast_list, 0) # broadcast 'stop' to all ranks
|
||||||
|
self.stop = broadcast_list[0]
|
||||||
|
if self.stop: # training time exceeded
|
||||||
|
break
|
||||||
|
|
||||||
# Log
|
# Log
|
||||||
mem = f'{torch.cuda.memory_reserved() / 1E9 if torch.cuda.is_available() else 0:.3g}G' # (GB)
|
mem = f'{torch.cuda.memory_reserved() / 1E9 if torch.cuda.is_available() else 0:.3g}G' # (GB)
|
||||||
loss_len = self.tloss.shape[0] if len(self.tloss.size()) else 1
|
loss_len = self.tloss.shape[0] if len(self.tloss.size()) else 1
|
||||||
@ -363,31 +378,37 @@ class BaseTrainer:
|
|||||||
self.run_callbacks('on_train_batch_end')
|
self.run_callbacks('on_train_batch_end')
|
||||||
|
|
||||||
self.lr = {f'lr/pg{ir}': x['lr'] for ir, x in enumerate(self.optimizer.param_groups)} # for loggers
|
self.lr = {f'lr/pg{ir}': x['lr'] for ir, x in enumerate(self.optimizer.param_groups)} # for loggers
|
||||||
|
|
||||||
with warnings.catch_warnings():
|
|
||||||
warnings.simplefilter('ignore') # suppress 'Detected lr_scheduler.step() before optimizer.step()'
|
|
||||||
self.scheduler.step()
|
|
||||||
self.run_callbacks('on_train_epoch_end')
|
self.run_callbacks('on_train_epoch_end')
|
||||||
|
|
||||||
if RANK in (-1, 0):
|
if RANK in (-1, 0):
|
||||||
|
final_epoch = epoch + 1 == self.epochs
|
||||||
|
self.ema.update_attr(self.model, include=['yaml', 'nc', 'args', 'names', 'stride', 'class_weights'])
|
||||||
|
|
||||||
# Validation
|
# Validation
|
||||||
self.ema.update_attr(self.model, include=['yaml', 'nc', 'args', 'names', 'stride', 'class_weights'])
|
if self.args.val or final_epoch or self.stopper.possible_stop or self.stop:
|
||||||
final_epoch = (epoch + 1 == self.epochs) or self.stopper.possible_stop
|
|
||||||
|
|
||||||
if self.args.val or final_epoch:
|
|
||||||
self.metrics, self.fitness = self.validate()
|
self.metrics, self.fitness = self.validate()
|
||||||
self.save_metrics(metrics={**self.label_loss_items(self.tloss), **self.metrics, **self.lr})
|
self.save_metrics(metrics={**self.label_loss_items(self.tloss), **self.metrics, **self.lr})
|
||||||
self.stop = self.stopper(epoch + 1, self.fitness)
|
self.stop |= self.stopper(epoch + 1, self.fitness)
|
||||||
|
if self.args.time:
|
||||||
|
self.stop |= (time.time() - self.train_time_start) > (self.args.time * 3600)
|
||||||
|
|
||||||
# Save model
|
# Save model
|
||||||
if self.args.save or (epoch + 1 == self.epochs):
|
if self.args.save or final_epoch:
|
||||||
self.save_model()
|
self.save_model()
|
||||||
self.run_callbacks('on_model_save')
|
self.run_callbacks('on_model_save')
|
||||||
|
|
||||||
tnow = time.time()
|
# Scheduler
|
||||||
self.epoch_time = tnow - self.epoch_time_start
|
t = time.time()
|
||||||
self.epoch_time_start = tnow
|
self.epoch_time = t - self.epoch_time_start
|
||||||
|
self.epoch_time_start = t
|
||||||
|
with warnings.catch_warnings():
|
||||||
|
warnings.simplefilter('ignore') # suppress 'Detected lr_scheduler.step() before optimizer.step()'
|
||||||
|
if self.args.time:
|
||||||
|
mean_epoch_time = (t - self.train_time_start) / (epoch - self.start_epoch + 1)
|
||||||
|
self.epochs = self.args.epochs = math.ceil(self.args.time * 3600 / mean_epoch_time)
|
||||||
|
self._setup_scheduler()
|
||||||
|
self.scheduler.last_epoch = self.epoch # do not move
|
||||||
|
self.stop |= epoch >= self.epochs # stop if exceeded epochs
|
||||||
|
self.scheduler.step()
|
||||||
self.run_callbacks('on_fit_epoch_end')
|
self.run_callbacks('on_fit_epoch_end')
|
||||||
torch.cuda.empty_cache() # clear GPU memory at end of epoch, may help reduce CUDA out of memory errors
|
torch.cuda.empty_cache() # clear GPU memory at end of epoch, may help reduce CUDA out of memory errors
|
||||||
|
|
||||||
@ -395,8 +416,7 @@ class BaseTrainer:
|
|||||||
if RANK != -1: # if DDP training
|
if RANK != -1: # if DDP training
|
||||||
broadcast_list = [self.stop if RANK == 0 else None]
|
broadcast_list = [self.stop if RANK == 0 else None]
|
||||||
dist.broadcast_object_list(broadcast_list, 0) # broadcast 'stop' to all ranks
|
dist.broadcast_object_list(broadcast_list, 0) # broadcast 'stop' to all ranks
|
||||||
if RANK != 0:
|
self.stop = broadcast_list[0]
|
||||||
self.stop = broadcast_list[0]
|
|
||||||
if self.stop:
|
if self.stop:
|
||||||
break # must break all DDP ranks
|
break # must break all DDP ranks
|
||||||
|
|
||||||
|
|||||||
@ -363,7 +363,7 @@ def de_parallel(model):
|
|||||||
|
|
||||||
def one_cycle(y1=0.0, y2=1.0, steps=100):
|
def one_cycle(y1=0.0, y2=1.0, steps=100):
|
||||||
"""Returns a lambda function for sinusoidal ramp from y1 to y2 https://arxiv.org/pdf/1812.01187.pdf."""
|
"""Returns a lambda function for sinusoidal ramp from y1 to y2 https://arxiv.org/pdf/1812.01187.pdf."""
|
||||||
return lambda x: ((1 - math.cos(x * math.pi / steps)) / 2) * (y2 - y1) + y1
|
return lambda x: max((1 - math.cos(x * math.pi / steps)) / 2, 0) * (y2 - y1) + y1
|
||||||
|
|
||||||
|
|
||||||
def init_seeds(seed=0, deterministic=False):
|
def init_seeds(seed=0, deterministic=False):
|
||||||
|
|||||||
Loading…
x
Reference in New Issue
Block a user