mirror of
https://github.com/THU-MIG/yolov10.git
synced 2026-01-20 00:15:29 +08:00
ultralytics 8.1.14 new YOLOv8-World models (#8054)
Signed-off-by: Glenn Jocher <glenn.jocher@ultralytics.com> Co-authored-by: UltralyticsAssistant <web@ultralytics.com> Co-authored-by: Glenn Jocher <glenn.jocher@ultralytics.com>
This commit is contained in:
parent
f9e9cdf2c3
commit
850ca8587f
@ -1,7 +1,7 @@
|
|||||||
---
|
---
|
||||||
comments: true
|
comments: true
|
||||||
description: Explore the diverse range of YOLO family, SAM, MobileSAM, FastSAM, YOLO-NAS, and RT-DETR models supported by Ultralytics. Get started with examples for both CLI and Python usage.
|
description: Explore the diverse range of YOLO family, SAM, MobileSAM, FastSAM, YOLO-NAS, YOLO-World and RT-DETR models supported by Ultralytics. Get started with examples for both CLI and Python usage.
|
||||||
keywords: Ultralytics, documentation, YOLO, SAM, MobileSAM, FastSAM, YOLO-NAS, RT-DETR, models, architectures, Python, CLI
|
keywords: Ultralytics, documentation, YOLO, SAM, MobileSAM, FastSAM, YOLO-NAS, RT-DETR, YOLO-World, models, architectures, Python, CLI
|
||||||
---
|
---
|
||||||
|
|
||||||
# Models Supported by Ultralytics
|
# Models Supported by Ultralytics
|
||||||
@ -23,6 +23,7 @@ Here are some of the key models supported:
|
|||||||
9. **[Fast Segment Anything Model (FastSAM)](fast-sam.md)**: FastSAM by Image & Video Analysis Group, Institute of Automation, Chinese Academy of Sciences.
|
9. **[Fast Segment Anything Model (FastSAM)](fast-sam.md)**: FastSAM by Image & Video Analysis Group, Institute of Automation, Chinese Academy of Sciences.
|
||||||
10. **[YOLO-NAS](yolo-nas.md)**: YOLO Neural Architecture Search (NAS) Models.
|
10. **[YOLO-NAS](yolo-nas.md)**: YOLO Neural Architecture Search (NAS) Models.
|
||||||
11. **[Realtime Detection Transformers (RT-DETR)](rtdetr.md)**: Baidu's PaddlePaddle Realtime Detection Transformer (RT-DETR) models.
|
11. **[Realtime Detection Transformers (RT-DETR)](rtdetr.md)**: Baidu's PaddlePaddle Realtime Detection Transformer (RT-DETR) models.
|
||||||
|
12. **[YOLO-World](yolo-world.md)**: Real-time Open Vocabulary Object Detection models from Tencent AI Lab.
|
||||||
|
|
||||||
<p align="center">
|
<p align="center">
|
||||||
<br>
|
<br>
|
||||||
|
|||||||
206
docs/en/models/yolo-world.md
Normal file
206
docs/en/models/yolo-world.md
Normal file
@ -0,0 +1,206 @@
|
|||||||
|
---
|
||||||
|
comments: true
|
||||||
|
description: Discover YOLO-World, a YOLOv8-based framework for real-time open-vocabulary object detection in images. It enhances user interaction, boosts computational efficiency, and adapts across various vision tasks.
|
||||||
|
keywords: YOLO-World, YOLOv8, machine learning, CNN-based framework, object detection, real-time detection, Ultralytics, vision tasks, image processing, industrial applications, user interaction
|
||||||
|
---
|
||||||
|
|
||||||
|
# YOLO-World Model
|
||||||
|
|
||||||
|
The YOLO-World Model introduces an advanced, real-time [Ultralytics](https://ultralytics.com) [YOLOv8](yolov8.md)-based approach for Open-Vocabulary Detection tasks. This innovation enables the detection of any object within an image based on descriptive texts. By significantly lowering computational demands while preserving competitive performance, YOLO-World emerges as a versatile tool for numerous vision-based applications.
|
||||||
|
|
||||||
|
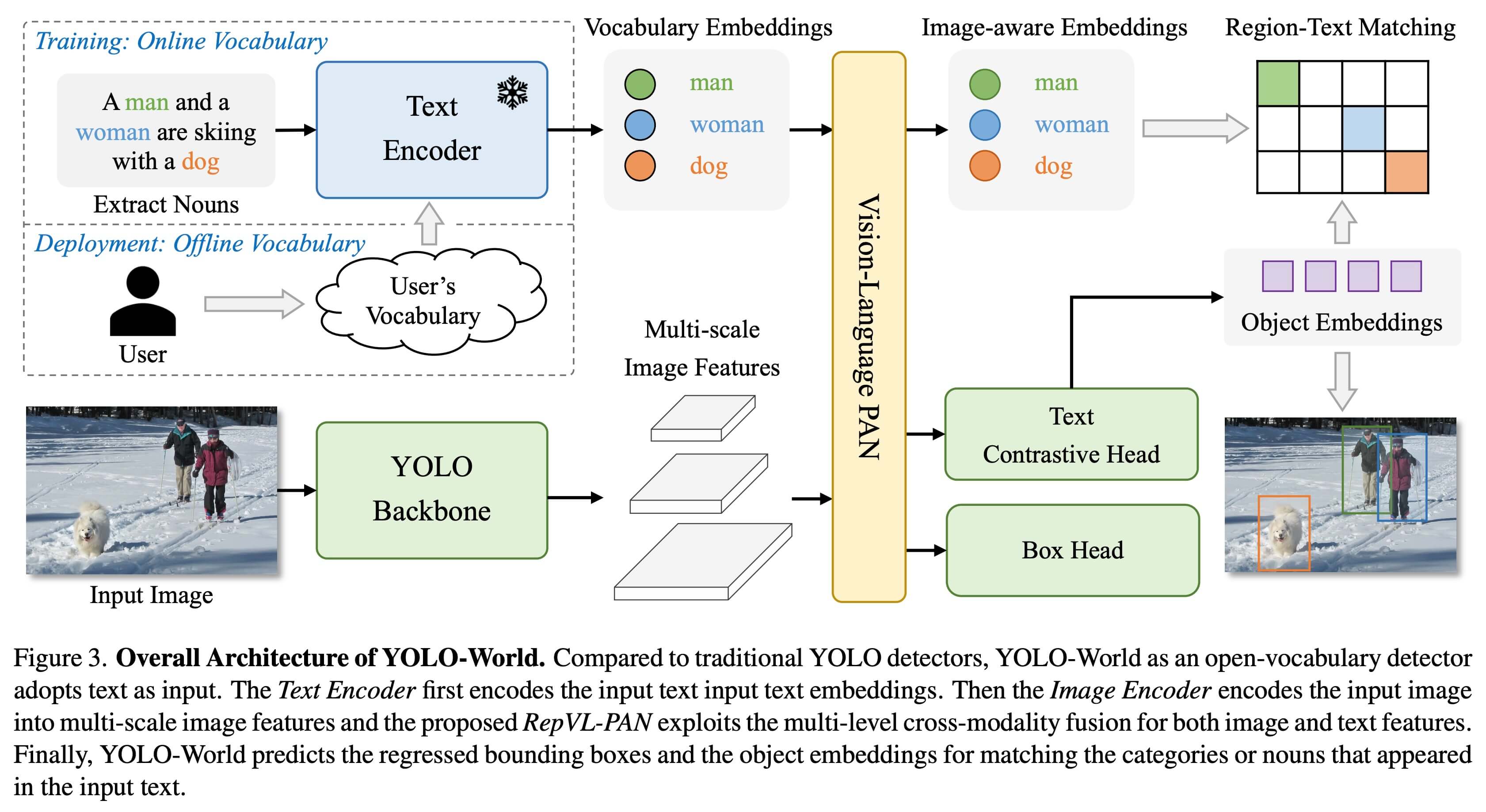
|
||||||
|
|
||||||
|
## Overview
|
||||||
|
|
||||||
|
YOLO-World tackles the challenges faced by traditional Open-Vocabulary detection models, which often rely on cumbersome Transformer models requiring extensive computational resources. These models' dependence on pre-defined object categories also restricts their utility in dynamic scenarios. YOLO-World revitalizes the YOLOv8 framework with open-vocabulary detection capabilities, employing vision-language modeling and pre-training on expansive datasets to excel at identifying a broad array of objects in zero-shot scenarios with unmatched efficiency.
|
||||||
|
|
||||||
|
## Key Features
|
||||||
|
|
||||||
|
1. **Real-time Solution:** Harnessing the computational speed of CNNs, YOLO-World delivers a swift open-vocabulary detection solution, catering to industries in need of immediate results.
|
||||||
|
|
||||||
|
2. **Efficiency and Performance:** YOLO-World slashes computational and resource requirements without sacrificing performance, offering a robust alternative to models like SAM but at a fraction of the computational cost, enabling real-time applications.
|
||||||
|
|
||||||
|
3. **Inference with Offline Vocabulary:** YOLO-World introduces a "prompt-then-detect" strategy, employing an offline vocabulary to enhance efficiency further. This approach enables the use of custom prompts computed apriori, including captions or categories, to be encoded and stored as offline vocabulary embeddings, streamlining the detection process.
|
||||||
|
|
||||||
|
4. **Powered by YOLOv8:** Built upon [Ultralytics YOLOv8](yolov8.md), YOLO-World leverages the latest advancements in real-time object detection to facilitate open-vocabulary detection with unparalleled accuracy and speed.
|
||||||
|
|
||||||
|
5. **Benchmark Excellence:** YOLO-World outperforms existing open-vocabulary detectors, including MDETR and GLIP series, in terms of speed and efficiency on standard benchmarks, showcasing YOLOv8's superior capability on a single NVIDIA V100 GPU.
|
||||||
|
|
||||||
|
6. **Versatile Applications:** YOLO-World's innovative approach unlocks new possibilities for a multitude of vision tasks, delivering speed improvements by orders of magnitude over existing methods.
|
||||||
|
|
||||||
|
## Available Models, Supported Tasks, and Operating Modes
|
||||||
|
|
||||||
|
This section details the models available with their specific pre-trained weights, the tasks they support, and their compatibility with various operating modes such as [Inference](../modes/predict.md), [Validation](../modes/val.md), [Training](../modes/train.md), and [Export](../modes/export.md), denoted by ✅ for supported modes and ❌ for unsupported modes.
|
||||||
|
|
||||||
|
!!! Note
|
||||||
|
|
||||||
|
All the YOLOv8-World weights have been directly migrated from the official [YOLO-World](https://github.com/AILab-CVC/YOLO-World) repository, highlighting their excellent contributions.
|
||||||
|
|
||||||
|
| Model Type | Pre-trained Weights | Tasks Supported | Inference | Validation | Training | Export |
|
||||||
|
|---------------|-----------------------------------------------------------------------------------------------------|----------------------------------------|-----------|------------|----------|--------|
|
||||||
|
| YOLOv8s-world | [yolov8s-world.pt](https://github.com/ultralytics/assets/releases/download/v8.1.0/yolov8s-world.pt) | [Object Detection](../tasks/detect.md) | ✅ | ✅ | ❌ | ❌ |
|
||||||
|
| YOLOv8m-world | [yolov8m-world.pt](https://github.com/ultralytics/assets/releases/download/v8.1.0/yolov8m-world.pt) | [Object Detection](../tasks/detect.md) | ✅ | ✅ | ❌ | ❌ |
|
||||||
|
| YOLOv8l-world | [yolov8l-world.pt](https://github.com/ultralytics/assets/releases/download/v8.1.0/yolov8l-world.pt) | [Object Detection](../tasks/detect.md) | ✅ | ✅ | ❌ | ❌ |
|
||||||
|
|
||||||
|
## Zero-shot Transfer on COCO Dataset
|
||||||
|
|
||||||
|
| Model Type | mAP | mAP50 | mAP75 |
|
||||||
|
|---------------|------|-------|-------|
|
||||||
|
| yolov8s-world | 37.4 | 52.0 | 40.6 |
|
||||||
|
| yolov8m-world | 42.0 | 57.0 | 45.6 |
|
||||||
|
| yolov8l-world | 45.7 | 61.3 | 49.8 |
|
||||||
|
|
||||||
|
## Usage Examples
|
||||||
|
|
||||||
|
The YOLO-World models are easy to integrate into your Python applications. Ultralytics provides user-friendly Python API and CLI commands to streamline development.
|
||||||
|
|
||||||
|
### Predict Usage
|
||||||
|
|
||||||
|
Object detection is straightforward with the `predict` method, as illustrated below:
|
||||||
|
|
||||||
|
!!! Example
|
||||||
|
|
||||||
|
=== "Python"
|
||||||
|
|
||||||
|
```python
|
||||||
|
from ultralytics import YOLOWorld
|
||||||
|
|
||||||
|
# Initialize a YOLO-World model
|
||||||
|
model = YOLOWorld('yolov8s-world.pt') # or select yolov8m/l-world.pt for different sizes
|
||||||
|
|
||||||
|
# Execute inference with the YOLOv8s-world model on the specified image
|
||||||
|
results = model.predict('path/to/image.jpg')
|
||||||
|
|
||||||
|
# Show results
|
||||||
|
results[0].show()
|
||||||
|
```
|
||||||
|
|
||||||
|
=== "CLI"
|
||||||
|
|
||||||
|
```bash
|
||||||
|
# Perform object detection using a YOLO-World model
|
||||||
|
yolo predict model=yolov8s-world.pt source=path/to/image.jpg imgsz=640
|
||||||
|
```
|
||||||
|
|
||||||
|
This snippet demonstrates the simplicity of loading a pre-trained model and running a prediction on an image.
|
||||||
|
|
||||||
|
### Val Usage
|
||||||
|
|
||||||
|
Model validation on a dataset is streamlined as follows:
|
||||||
|
|
||||||
|
!!! Example
|
||||||
|
|
||||||
|
=== "Python"
|
||||||
|
|
||||||
|
```python
|
||||||
|
from ultralytics import YOLO
|
||||||
|
|
||||||
|
# Create a YOLO-World model
|
||||||
|
model = YOLO('yolov8s-world.pt') # or select yolov8m/l-world.pt for different sizes
|
||||||
|
|
||||||
|
# Conduct model validation on the COCO8 example dataset
|
||||||
|
metrics = model.val(data='coco8.yaml')
|
||||||
|
```
|
||||||
|
|
||||||
|
=== "CLI"
|
||||||
|
|
||||||
|
```bash
|
||||||
|
# Validate a YOLO-World model on the COCO8 dataset with a specified image size
|
||||||
|
yolo val model=yolov8s-world.pt data=coco8.yaml imgsz=640
|
||||||
|
```
|
||||||
|
|
||||||
|
!!! Note
|
||||||
|
|
||||||
|
The YOLO-World models provided by Ultralytics come pre-configured with [COCO dataset](../datasets/detect/coco) categories as part of their offline vocabulary, enhancing efficiency for immediate application. This integration allows the YOLOv8-World models to directly recognize and predict the 80 standard categories defined in the COCO dataset without requiring additional setup or customization.
|
||||||
|
|
||||||
|
### Set prompts
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
The YOLO-World framework allows for the dynamic specification of classes through custom prompts, empowering users to tailor the model to their specific needs **without retraining**. This feature is particularly useful for adapting the model to new domains or specific tasks that were not originally part of the training data. By setting custom prompts, users can essentially guide the model's focus towards objects of interest, enhancing the relevance and accuracy of the detection results.
|
||||||
|
|
||||||
|
For instance, if your application only requires detecting 'person' and 'bus' objects, you can specify these classes directly:
|
||||||
|
|
||||||
|
!!! Example
|
||||||
|
|
||||||
|
=== "Custom Inference Prompts"
|
||||||
|
|
||||||
|
```python
|
||||||
|
from ultralytics import YOLO
|
||||||
|
|
||||||
|
# Initialize a YOLO-World model
|
||||||
|
model = YOLO('yolov8s-world.pt') # or choose yolov8m/l-world.pt
|
||||||
|
|
||||||
|
# Define custom classes
|
||||||
|
model.set_classes(["person", "bus"])
|
||||||
|
|
||||||
|
# Execute prediction for specified categories on an image
|
||||||
|
results = model.predict('path/to/image.jpg')
|
||||||
|
|
||||||
|
# Show results
|
||||||
|
results[0].show()
|
||||||
|
```
|
||||||
|
|
||||||
|
You can also save a model after setting custom classes. By doing this you create a version of the YOLO-World model that is specialized for your specific use case. This process embeds your custom class definitions directly into the model file, making the model ready to use with your specified classes without further adjustments. Follow these steps to save and load your custom YOLOv8 model:
|
||||||
|
|
||||||
|
!!! Example
|
||||||
|
|
||||||
|
=== "Persisting Models with Custom Vocabulary"
|
||||||
|
|
||||||
|
First load a YOLO-World model, set custom classes for it and save it:
|
||||||
|
|
||||||
|
```python
|
||||||
|
from ultralytics import YOLO
|
||||||
|
|
||||||
|
# Initialize a YOLO-World model
|
||||||
|
model = YOLO('yolov8s-world.pt') # or select yolov8m/l-world.pt
|
||||||
|
|
||||||
|
# Define custom classes
|
||||||
|
model.set_classes(["person", "bus"])
|
||||||
|
|
||||||
|
# Save the model with the defined offline vocabulary
|
||||||
|
model.save("custom_yolov8s.pt")
|
||||||
|
```
|
||||||
|
|
||||||
|
After saving, the custom_yolov8s.pt model behaves like any other pre-trained YOLOv8 model but with a key difference: it is now optimized to detect only the classes you have defined. This customization can significantly improve detection performance and efficiency for your specific application scenarios.
|
||||||
|
|
||||||
|
```python
|
||||||
|
from ultralytics import YOLO
|
||||||
|
|
||||||
|
# Load your custom model
|
||||||
|
model = YOLO('custom_yolov8s.pt')
|
||||||
|
|
||||||
|
# Run inference to detect your custom classes
|
||||||
|
results = model.predict('path/to/image.jpg')
|
||||||
|
|
||||||
|
# Show results
|
||||||
|
results[0].show()
|
||||||
|
```
|
||||||
|
|
||||||
|
### Benefits of Saving with Custom Vocabulary
|
||||||
|
|
||||||
|
- **Efficiency**: Streamlines the detection process by focusing on relevant objects, reducing computational overhead and speeding up inference.
|
||||||
|
- **Flexibility**: Allows for easy adaptation of the model to new or niche detection tasks without the need for extensive retraining or data collection.
|
||||||
|
- **Simplicity**: Simplifies deployment by eliminating the need to repeatedly specify custom classes at runtime, making the model directly usable with its embedded vocabulary.
|
||||||
|
- **Performance**: Enhances detection accuracy for specified classes by focusing the model's attention and resources on recognizing the defined objects.
|
||||||
|
|
||||||
|
This approach provides a powerful means of customizing state-of-the-art object detection models for specific tasks, making advanced AI more accessible and applicable to a broader range of practical applications.
|
||||||
|
|
||||||
|
## Citations and Acknowledgements
|
||||||
|
|
||||||
|
We extend our gratitude to the [Tencent AILab Computer Vision Center](https://ai.tencent.com/) for their pioneering work in real-time open-vocabulary object detection with YOLO-World:
|
||||||
|
|
||||||
|
!!! Quote ""
|
||||||
|
|
||||||
|
=== "BibTeX"
|
||||||
|
|
||||||
|
```bibtex
|
||||||
|
@article{cheng2024yolow,
|
||||||
|
title={YOLO-World: Real-Time Open-Vocabulary Object Detection},
|
||||||
|
author={Cheng, Tianheng and Song, Lin and Ge, Yixiao and Liu, Wenyu and Wang, Xinggang and Shan, Ying},
|
||||||
|
journal={arXiv preprint arXiv:2401.17270},
|
||||||
|
year={2024}
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
For further reading, the original YOLO-World paper is available on [arXiv](https://arxiv.org/pdf/2401.17270v2.pdf). The project's source code and additional resources can be accessed via their [GitHub repository](https://github.com/AILab-CVC/YOLO-World). We appreciate their commitment to advancing the field and sharing their valuable insights with the community.
|
||||||
@ -1,3 +1,4 @@
|
|||||||
|
1185102784@qq.com: Laughing-q
|
||||||
1579093407@qq.com: null
|
1579093407@qq.com: null
|
||||||
17216799+ouphi@users.noreply.github.com: ouphi
|
17216799+ouphi@users.noreply.github.com: ouphi
|
||||||
17316848+maianumerosky@users.noreply.github.com: maianumerosky
|
17316848+maianumerosky@users.noreply.github.com: maianumerosky
|
||||||
|
|||||||
@ -226,6 +226,7 @@ nav:
|
|||||||
- FastSAM (Fast Segment Anything Model): models/fast-sam.md
|
- FastSAM (Fast Segment Anything Model): models/fast-sam.md
|
||||||
- YOLO-NAS (Neural Architecture Search): models/yolo-nas.md
|
- YOLO-NAS (Neural Architecture Search): models/yolo-nas.md
|
||||||
- RT-DETR (Realtime Detection Transformer): models/rtdetr.md
|
- RT-DETR (Realtime Detection Transformer): models/rtdetr.md
|
||||||
|
- YOLO-World (Real-Time Open-Vocabulary Object Detection): models/yolo-world.md
|
||||||
- Datasets:
|
- Datasets:
|
||||||
- datasets/index.md
|
- datasets/index.md
|
||||||
- NEW 🚀 Explorer:
|
- NEW 🚀 Explorer:
|
||||||
|
|||||||
@ -1,9 +1,9 @@
|
|||||||
# Ultralytics YOLO 🚀, AGPL-3.0 license
|
# Ultralytics YOLO 🚀, AGPL-3.0 license
|
||||||
|
|
||||||
__version__ = "8.1.13"
|
__version__ = "8.1.14"
|
||||||
|
|
||||||
from ultralytics.data.explorer.explorer import Explorer
|
from ultralytics.data.explorer.explorer import Explorer
|
||||||
from ultralytics.models import RTDETR, SAM, YOLO
|
from ultralytics.models import RTDETR, SAM, YOLO, YOLOWorld
|
||||||
from ultralytics.models.fastsam import FastSAM
|
from ultralytics.models.fastsam import FastSAM
|
||||||
from ultralytics.models.nas import NAS
|
from ultralytics.models.nas import NAS
|
||||||
from ultralytics.utils import ASSETS, SETTINGS as settings
|
from ultralytics.utils import ASSETS, SETTINGS as settings
|
||||||
@ -14,6 +14,7 @@ __all__ = (
|
|||||||
"__version__",
|
"__version__",
|
||||||
"ASSETS",
|
"ASSETS",
|
||||||
"YOLO",
|
"YOLO",
|
||||||
|
"YOLOWorld",
|
||||||
"NAS",
|
"NAS",
|
||||||
"SAM",
|
"SAM",
|
||||||
"FastSAM",
|
"FastSAM",
|
||||||
|
|||||||
46
ultralytics/cfg/models/v8/yolov8-world-t2i.yaml
Normal file
46
ultralytics/cfg/models/v8/yolov8-world-t2i.yaml
Normal file
@ -0,0 +1,46 @@
|
|||||||
|
# Ultralytics YOLO 🚀, AGPL-3.0 license
|
||||||
|
# YOLOv8 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect
|
||||||
|
|
||||||
|
# Parameters
|
||||||
|
nc: 80 # number of classes
|
||||||
|
scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n'
|
||||||
|
# [depth, width, max_channels]
|
||||||
|
n: [0.33, 0.25, 1024] # YOLOv8n summary: 225 layers, 3157200 parameters, 3157184 gradients, 8.9 GFLOPs
|
||||||
|
s: [0.33, 0.50, 1024] # YOLOv8s summary: 225 layers, 11166560 parameters, 11166544 gradients, 28.8 GFLOPs
|
||||||
|
m: [0.67, 0.75, 768] # YOLOv8m summary: 295 layers, 25902640 parameters, 25902624 gradients, 79.3 GFLOPs
|
||||||
|
l: [1.00, 1.00, 512] # YOLOv8l summary: 365 layers, 43691520 parameters, 43691504 gradients, 165.7 GFLOPs
|
||||||
|
x: [1.00, 1.25, 512] # YOLOv8x summary: 365 layers, 68229648 parameters, 68229632 gradients, 258.5 GFLOPs
|
||||||
|
|
||||||
|
# YOLOv8.0n backbone
|
||||||
|
backbone:
|
||||||
|
# [from, repeats, module, args]
|
||||||
|
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
|
||||||
|
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
|
||||||
|
- [-1, 3, C2f, [128, True]]
|
||||||
|
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
|
||||||
|
- [-1, 6, C2f, [256, True]]
|
||||||
|
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
|
||||||
|
- [-1, 6, C2f, [512, True]]
|
||||||
|
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
|
||||||
|
- [-1, 3, C2f, [1024, True]]
|
||||||
|
- [-1, 1, SPPF, [1024, 5]] # 9
|
||||||
|
|
||||||
|
# YOLOv8.0n head
|
||||||
|
head:
|
||||||
|
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
|
||||||
|
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
|
||||||
|
- [-1, 2, C2fAttn, [512, 256, 8]] # 12
|
||||||
|
|
||||||
|
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
|
||||||
|
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
|
||||||
|
- [-1, 2, C2fAttn, [256, 128, 4]] # 15 (P3/8-small)
|
||||||
|
|
||||||
|
- [15, 1, Conv, [256, 3, 2]]
|
||||||
|
- [[-1, 12], 1, Concat, [1]] # cat head P4
|
||||||
|
- [-1, 2, C2fAttn, [512, 256, 8]] # 18 (P4/16-medium)
|
||||||
|
|
||||||
|
- [-1, 1, Conv, [512, 3, 2]]
|
||||||
|
- [[-1, 9], 1, Concat, [1]] # cat head P5
|
||||||
|
- [-1, 2, C2fAttn, [1024, 512, 16]] # 21 (P5/32-large)
|
||||||
|
|
||||||
|
- [[15, 18, 21], 1, WorldDetect, [nc, 512, True]] # Detect(P3, P4, P5)
|
||||||
48
ultralytics/cfg/models/v8/yolov8-world.yaml
Normal file
48
ultralytics/cfg/models/v8/yolov8-world.yaml
Normal file
@ -0,0 +1,48 @@
|
|||||||
|
# Ultralytics YOLO 🚀, AGPL-3.0 license
|
||||||
|
# YOLOv8 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect
|
||||||
|
|
||||||
|
# Parameters
|
||||||
|
nc: 80 # number of classes
|
||||||
|
scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n'
|
||||||
|
# [depth, width, max_channels]
|
||||||
|
n: [0.33, 0.25, 1024] # YOLOv8n summary: 225 layers, 3157200 parameters, 3157184 gradients, 8.9 GFLOPs
|
||||||
|
s: [0.33, 0.50, 1024] # YOLOv8s summary: 225 layers, 11166560 parameters, 11166544 gradients, 28.8 GFLOPs
|
||||||
|
m: [0.67, 0.75, 768] # YOLOv8m summary: 295 layers, 25902640 parameters, 25902624 gradients, 79.3 GFLOPs
|
||||||
|
l: [1.00, 1.00, 512] # YOLOv8l summary: 365 layers, 43691520 parameters, 43691504 gradients, 165.7 GFLOPs
|
||||||
|
x: [1.00, 1.25, 512] # YOLOv8x summary: 365 layers, 68229648 parameters, 68229632 gradients, 258.5 GFLOPs
|
||||||
|
|
||||||
|
# YOLOv8.0n backbone
|
||||||
|
backbone:
|
||||||
|
# [from, repeats, module, args]
|
||||||
|
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
|
||||||
|
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
|
||||||
|
- [-1, 3, C2f, [128, True]]
|
||||||
|
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
|
||||||
|
- [-1, 6, C2f, [256, True]]
|
||||||
|
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
|
||||||
|
- [-1, 6, C2f, [512, True]]
|
||||||
|
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
|
||||||
|
- [-1, 3, C2f, [1024, True]]
|
||||||
|
- [-1, 1, SPPF, [1024, 5]] # 9
|
||||||
|
|
||||||
|
# YOLOv8.0n head
|
||||||
|
head:
|
||||||
|
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
|
||||||
|
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
|
||||||
|
- [-1, 3, C2fAttn, [512, 256, 8]] # 12
|
||||||
|
|
||||||
|
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
|
||||||
|
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
|
||||||
|
- [-1, 3, C2fAttn, [256, 128, 4]] # 15 (P3/8-small)
|
||||||
|
|
||||||
|
- [[15, 12, 9], 1, ImagePoolingAttn, [256]] # 16 (P3/8-small)
|
||||||
|
|
||||||
|
- [15, 1, Conv, [256, 3, 2]]
|
||||||
|
- [[-1, 12], 1, Concat, [1]] # cat head P4
|
||||||
|
- [-1, 3, C2fAttn, [512, 256, 8]] # 19 (P4/16-medium)
|
||||||
|
|
||||||
|
- [-1, 1, Conv, [512, 3, 2]]
|
||||||
|
- [[-1, 9], 1, Concat, [1]] # cat head P5
|
||||||
|
- [-1, 3, C2fAttn, [1024, 512, 16]] # 22 (P5/32-large)
|
||||||
|
|
||||||
|
- [[15, 19, 22], 1, WorldDetect, [nc, 512, False]] # Detect(P3, P4, P5)
|
||||||
@ -216,7 +216,7 @@ class Exporter:
|
|||||||
model.float()
|
model.float()
|
||||||
model = model.fuse()
|
model = model.fuse()
|
||||||
for m in model.modules():
|
for m in model.modules():
|
||||||
if isinstance(m, (Detect, RTDETRDecoder)): # Segment and Pose use Detect base class
|
if isinstance(m, (Detect, RTDETRDecoder)): # includes all Detect subclasses like Segment, Pose, OBB
|
||||||
m.dynamic = self.args.dynamic
|
m.dynamic = self.args.dynamic
|
||||||
m.export = True
|
m.export = True
|
||||||
m.format = self.args.format
|
m.format = self.args.format
|
||||||
@ -455,8 +455,8 @@ class Exporter:
|
|||||||
LOGGER.warning(f"{prefix} WARNING ⚠️ >300 images recommended for INT8 calibration, found {n} images.")
|
LOGGER.warning(f"{prefix} WARNING ⚠️ >300 images recommended for INT8 calibration, found {n} images.")
|
||||||
quantization_dataset = nncf.Dataset(dataset, transform_fn)
|
quantization_dataset = nncf.Dataset(dataset, transform_fn)
|
||||||
ignored_scope = None
|
ignored_scope = None
|
||||||
if isinstance(self.model.model[-1], (Detect, RTDETRDecoder)): # Segment and Pose use Detect base class
|
if isinstance(self.model.model[-1], (Detect, RTDETRDecoder)):
|
||||||
# get detection module name in onnx
|
# Includes all Detect subclasses like Segment, Pose, OBB, WorldDetect
|
||||||
head_module_name = ".".join(list(self.model.named_modules())[-1][0].split(".")[:2])
|
head_module_name = ".".join(list(self.model.named_modules())[-1][0].split(".")[:2])
|
||||||
|
|
||||||
ignored_scope = nncf.IgnoredScope( # ignore operations
|
ignored_scope = nncf.IgnoredScope( # ignore operations
|
||||||
|
|||||||
@ -2,6 +2,6 @@
|
|||||||
|
|
||||||
from .rtdetr import RTDETR
|
from .rtdetr import RTDETR
|
||||||
from .sam import SAM
|
from .sam import SAM
|
||||||
from .yolo import YOLO
|
from .yolo import YOLO, YOLOWorld
|
||||||
|
|
||||||
__all__ = "YOLO", "RTDETR", "SAM" # allow simpler import
|
__all__ = "YOLO", "RTDETR", "SAM", "YOLOWorld" # allow simpler import
|
||||||
|
|||||||
@ -31,7 +31,7 @@ class FastSAMPrompt:
|
|||||||
|
|
||||||
# Import and assign clip
|
# Import and assign clip
|
||||||
try:
|
try:
|
||||||
import clip # for linear_assignment
|
import clip
|
||||||
except ImportError:
|
except ImportError:
|
||||||
from ultralytics.utils.checks import check_requirements
|
from ultralytics.utils.checks import check_requirements
|
||||||
|
|
||||||
|
|||||||
@ -2,6 +2,6 @@
|
|||||||
|
|
||||||
from ultralytics.models.yolo import classify, detect, obb, pose, segment
|
from ultralytics.models.yolo import classify, detect, obb, pose, segment
|
||||||
|
|
||||||
from .model import YOLO
|
from .model import YOLO, YOLOWorld
|
||||||
|
|
||||||
__all__ = "classify", "segment", "detect", "pose", "obb", "YOLO"
|
__all__ = "classify", "segment", "detect", "pose", "obb", "YOLO", "YOLOWorld"
|
||||||
|
|||||||
@ -1,13 +1,27 @@
|
|||||||
# Ultralytics YOLO 🚀, AGPL-3.0 license
|
# Ultralytics YOLO 🚀, AGPL-3.0 license
|
||||||
|
|
||||||
|
from pathlib import Path
|
||||||
|
|
||||||
from ultralytics.engine.model import Model
|
from ultralytics.engine.model import Model
|
||||||
from ultralytics.models import yolo
|
from ultralytics.models import yolo
|
||||||
from ultralytics.nn.tasks import ClassificationModel, DetectionModel, OBBModel, PoseModel, SegmentationModel
|
from ultralytics.nn.tasks import ClassificationModel, DetectionModel, OBBModel, PoseModel, SegmentationModel, WorldModel
|
||||||
|
from ultralytics.utils import yaml_load, ROOT
|
||||||
|
|
||||||
|
|
||||||
class YOLO(Model):
|
class YOLO(Model):
|
||||||
"""YOLO (You Only Look Once) object detection model."""
|
"""YOLO (You Only Look Once) object detection model."""
|
||||||
|
|
||||||
|
def __init__(self, model="yolov8n.pt", task=None, verbose=False):
|
||||||
|
"""Initialize YOLO model, switching to YOLOWorld if model filename contains '-world'."""
|
||||||
|
stem = Path(model).stem # filename stem without suffix, i.e. "yolov8n"
|
||||||
|
if "-world" in stem:
|
||||||
|
new_instance = YOLOWorld(model)
|
||||||
|
self.__class__ = type(new_instance)
|
||||||
|
self.__dict__ = new_instance.__dict__
|
||||||
|
else:
|
||||||
|
# Continue with default YOLO initialization
|
||||||
|
super().__init__(model=model, task=task, verbose=verbose)
|
||||||
|
|
||||||
@property
|
@property
|
||||||
def task_map(self):
|
def task_map(self):
|
||||||
"""Map head to model, trainer, validator, and predictor classes."""
|
"""Map head to model, trainer, validator, and predictor classes."""
|
||||||
@ -43,3 +57,49 @@ class YOLO(Model):
|
|||||||
"predictor": yolo.obb.OBBPredictor,
|
"predictor": yolo.obb.OBBPredictor,
|
||||||
},
|
},
|
||||||
}
|
}
|
||||||
|
|
||||||
|
|
||||||
|
class YOLOWorld(Model):
|
||||||
|
"""YOLO-World object detection model."""
|
||||||
|
|
||||||
|
def __init__(self, model="yolov8s-world.pt") -> None:
|
||||||
|
"""
|
||||||
|
Initializes the YOLOv8-World model with the given pre-trained model file. Supports *.pt and *.yaml formats.
|
||||||
|
|
||||||
|
Args:
|
||||||
|
model (str): Path to the pre-trained model. Defaults to 'yolov8s-world.pt'.
|
||||||
|
"""
|
||||||
|
super().__init__(model=model, task="detect")
|
||||||
|
|
||||||
|
# Assign default COCO class names
|
||||||
|
self.model.names = yaml_load(ROOT / "cfg/datasets/coco8.yaml").get("names")
|
||||||
|
|
||||||
|
@property
|
||||||
|
def task_map(self):
|
||||||
|
"""Map head to model, validator, and predictor classes."""
|
||||||
|
return {
|
||||||
|
"detect": {
|
||||||
|
"model": WorldModel,
|
||||||
|
"validator": yolo.detect.DetectionValidator,
|
||||||
|
"predictor": yolo.detect.DetectionPredictor,
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
def set_classes(self, classes):
|
||||||
|
"""
|
||||||
|
Set classes.
|
||||||
|
|
||||||
|
Args:
|
||||||
|
classes (List(str)): A list of categories i.e ["person"].
|
||||||
|
"""
|
||||||
|
self.model.set_classes(classes)
|
||||||
|
# Remove background if it's given
|
||||||
|
background = " "
|
||||||
|
if background in classes:
|
||||||
|
classes.remove(background)
|
||||||
|
self.model.names = classes
|
||||||
|
|
||||||
|
# Reset method class names
|
||||||
|
# self.predictor = None # reset predictor otherwise old names remain
|
||||||
|
if self.predictor:
|
||||||
|
self.predictor.model.names = classes
|
||||||
|
|||||||
@ -28,6 +28,8 @@ from .block import (
|
|||||||
Bottleneck,
|
Bottleneck,
|
||||||
BottleneckCSP,
|
BottleneckCSP,
|
||||||
C2f,
|
C2f,
|
||||||
|
C2fAttn,
|
||||||
|
ImagePoolingAttn,
|
||||||
C3Ghost,
|
C3Ghost,
|
||||||
C3x,
|
C3x,
|
||||||
GhostBottleneck,
|
GhostBottleneck,
|
||||||
@ -36,6 +38,8 @@ from .block import (
|
|||||||
Proto,
|
Proto,
|
||||||
RepC3,
|
RepC3,
|
||||||
ResNetLayer,
|
ResNetLayer,
|
||||||
|
ContrastiveHead,
|
||||||
|
BNContrastiveHead,
|
||||||
)
|
)
|
||||||
from .conv import (
|
from .conv import (
|
||||||
CBAM,
|
CBAM,
|
||||||
@ -52,7 +56,7 @@ from .conv import (
|
|||||||
RepConv,
|
RepConv,
|
||||||
SpatialAttention,
|
SpatialAttention,
|
||||||
)
|
)
|
||||||
from .head import OBB, Classify, Detect, Pose, RTDETRDecoder, Segment
|
from .head import OBB, Classify, Detect, Pose, RTDETRDecoder, Segment, WorldDetect
|
||||||
from .transformer import (
|
from .transformer import (
|
||||||
AIFI,
|
AIFI,
|
||||||
MLP,
|
MLP,
|
||||||
@ -93,6 +97,7 @@ __all__ = (
|
|||||||
"C2",
|
"C2",
|
||||||
"C3",
|
"C3",
|
||||||
"C2f",
|
"C2f",
|
||||||
|
"C2fAttn",
|
||||||
"C3x",
|
"C3x",
|
||||||
"C3TR",
|
"C3TR",
|
||||||
"C3Ghost",
|
"C3Ghost",
|
||||||
@ -114,4 +119,8 @@ __all__ = (
|
|||||||
"MLP",
|
"MLP",
|
||||||
"ResNetLayer",
|
"ResNetLayer",
|
||||||
"OBB",
|
"OBB",
|
||||||
|
"WorldDetect",
|
||||||
|
"ImagePoolingAttn",
|
||||||
|
"ContrastiveHead",
|
||||||
|
"BNContrastiveHead",
|
||||||
)
|
)
|
||||||
|
|||||||
@ -18,6 +18,10 @@ __all__ = (
|
|||||||
"C2",
|
"C2",
|
||||||
"C3",
|
"C3",
|
||||||
"C2f",
|
"C2f",
|
||||||
|
"C2fAttn",
|
||||||
|
"ImagePoolingAttn",
|
||||||
|
"ContrastiveHead",
|
||||||
|
"BNContrastiveHead",
|
||||||
"C3x",
|
"C3x",
|
||||||
"C3TR",
|
"C3TR",
|
||||||
"C3Ghost",
|
"C3Ghost",
|
||||||
@ -390,3 +394,157 @@ class ResNetLayer(nn.Module):
|
|||||||
def forward(self, x):
|
def forward(self, x):
|
||||||
"""Forward pass through the ResNet layer."""
|
"""Forward pass through the ResNet layer."""
|
||||||
return self.layer(x)
|
return self.layer(x)
|
||||||
|
|
||||||
|
|
||||||
|
class MaxSigmoidAttnBlock(nn.Module):
|
||||||
|
"""Max Sigmoid attention block."""
|
||||||
|
|
||||||
|
def __init__(self, c1, c2, nh=1, ec=128, gc=512, scale=False):
|
||||||
|
"""Initializes MaxSigmoidAttnBlock with specified arguments."""
|
||||||
|
super().__init__()
|
||||||
|
self.nh = nh
|
||||||
|
self.hc = c2 // nh
|
||||||
|
self.ec = Conv(c1, ec, k=1, act=False) if c1 != ec else None
|
||||||
|
self.gl = nn.Linear(gc, ec)
|
||||||
|
self.bias = nn.Parameter(torch.zeros(nh))
|
||||||
|
self.proj_conv = Conv(c1, c2, k=3, s=1, act=False)
|
||||||
|
self.scale = nn.Parameter(torch.ones(1, nh, 1, 1)) if scale else 1.0
|
||||||
|
|
||||||
|
def forward(self, x, guide):
|
||||||
|
"""Forward process."""
|
||||||
|
bs, _, h, w = x.shape
|
||||||
|
|
||||||
|
guide = self.gl(guide)
|
||||||
|
guide = guide.view(bs, -1, self.nh, self.hc)
|
||||||
|
embed = self.ec(x) if self.ec is not None else x
|
||||||
|
embed = embed.view(bs, self.nh, self.hc, h, w)
|
||||||
|
|
||||||
|
aw = torch.einsum("bmchw,bnmc->bmhwn", embed, guide)
|
||||||
|
aw = aw.max(dim=-1)[0]
|
||||||
|
aw = aw / (self.hc**0.5)
|
||||||
|
aw = aw + self.bias[None, :, None, None]
|
||||||
|
aw = aw.sigmoid() * self.scale
|
||||||
|
|
||||||
|
x = self.proj_conv(x)
|
||||||
|
x = x.view(bs, self.nh, -1, h, w)
|
||||||
|
x = x * aw.unsqueeze(2)
|
||||||
|
return x.view(bs, -1, h, w)
|
||||||
|
|
||||||
|
|
||||||
|
class C2fAttn(nn.Module):
|
||||||
|
"""C2f module with an additional attn module."""
|
||||||
|
|
||||||
|
def __init__(self, c1, c2, n=1, ec=128, nh=1, gc=512, shortcut=False, g=1, e=0.5):
|
||||||
|
"""Initialize CSP bottleneck layer with two convolutions with arguments ch_in, ch_out, number, shortcut, groups,
|
||||||
|
expansion.
|
||||||
|
"""
|
||||||
|
super().__init__()
|
||||||
|
self.c = int(c2 * e) # hidden channels
|
||||||
|
self.cv1 = Conv(c1, 2 * self.c, 1, 1)
|
||||||
|
self.cv2 = Conv((3 + n) * self.c, c2, 1) # optional act=FReLU(c2)
|
||||||
|
self.m = nn.ModuleList(Bottleneck(self.c, self.c, shortcut, g, k=((3, 3), (3, 3)), e=1.0) for _ in range(n))
|
||||||
|
self.attn = MaxSigmoidAttnBlock(self.c, self.c, gc=gc, ec=ec, nh=nh)
|
||||||
|
|
||||||
|
def forward(self, x, guide):
|
||||||
|
"""Forward pass through C2f layer."""
|
||||||
|
y = list(self.cv1(x).chunk(2, 1))
|
||||||
|
y.extend(m(y[-1]) for m in self.m)
|
||||||
|
y.append(self.attn(y[-1], guide))
|
||||||
|
return self.cv2(torch.cat(y, 1))
|
||||||
|
|
||||||
|
def forward_split(self, x, guide):
|
||||||
|
"""Forward pass using split() instead of chunk()."""
|
||||||
|
y = list(self.cv1(x).split((self.c, self.c), 1))
|
||||||
|
y.extend(m(y[-1]) for m in self.m)
|
||||||
|
y.append(self.attn(y[-1], guide))
|
||||||
|
return self.cv2(torch.cat(y, 1))
|
||||||
|
|
||||||
|
|
||||||
|
class ImagePoolingAttn(nn.Module):
|
||||||
|
"""ImagePoolingAttn: Enhance the text embeddings with image-aware information."""
|
||||||
|
|
||||||
|
def __init__(self, ec=256, ch=(), ct=512, nh=8, k=3, scale=False):
|
||||||
|
"""Initializes ImagePoolingAttn with specified arguments."""
|
||||||
|
super().__init__()
|
||||||
|
|
||||||
|
nf = len(ch)
|
||||||
|
self.query = nn.Sequential(nn.LayerNorm(ct), nn.Linear(ct, ec))
|
||||||
|
self.key = nn.Sequential(nn.LayerNorm(ec), nn.Linear(ec, ec))
|
||||||
|
self.value = nn.Sequential(nn.LayerNorm(ec), nn.Linear(ec, ec))
|
||||||
|
self.proj = nn.Linear(ec, ct)
|
||||||
|
self.scale = nn.Parameter(torch.tensor([0.0]), requires_grad=True) if scale else 1.0
|
||||||
|
self.projections = nn.ModuleList([nn.Conv2d(in_channels, ec, kernel_size=1) for in_channels in ch])
|
||||||
|
self.im_pools = nn.ModuleList([nn.AdaptiveMaxPool2d((k, k)) for _ in range(nf)])
|
||||||
|
self.ec = ec
|
||||||
|
self.nh = nh
|
||||||
|
self.nf = nf
|
||||||
|
self.hc = ec // nh
|
||||||
|
self.k = k
|
||||||
|
|
||||||
|
def forward(self, x, text):
|
||||||
|
"""Executes attention mechanism on input tensor x and guide tensor."""
|
||||||
|
bs = x[0].shape[0]
|
||||||
|
assert len(x) == self.nf
|
||||||
|
num_patches = self.k**2
|
||||||
|
x = [pool(proj(x)).view(bs, -1, num_patches) for (x, proj, pool) in zip(x, self.projections, self.im_pools)]
|
||||||
|
x = torch.cat(x, dim=-1).transpose(1, 2)
|
||||||
|
q = self.query(text)
|
||||||
|
k = self.key(x)
|
||||||
|
v = self.value(x)
|
||||||
|
|
||||||
|
# q = q.reshape(1, text.shape[1], self.nh, self.hc).repeat(bs, 1, 1, 1)
|
||||||
|
q = q.reshape(bs, -1, self.nh, self.hc)
|
||||||
|
k = k.reshape(bs, -1, self.nh, self.hc)
|
||||||
|
v = v.reshape(bs, -1, self.nh, self.hc)
|
||||||
|
|
||||||
|
aw = torch.einsum("bnmc,bkmc->bmnk", q, k)
|
||||||
|
aw = aw / (self.hc**0.5)
|
||||||
|
aw = F.softmax(aw, dim=-1)
|
||||||
|
|
||||||
|
x = torch.einsum("bmnk,bkmc->bnmc", aw, v)
|
||||||
|
x = self.proj(x.reshape(bs, -1, self.ec))
|
||||||
|
return x * self.scale + text
|
||||||
|
|
||||||
|
|
||||||
|
class ContrastiveHead(nn.Module):
|
||||||
|
"""Contrastive Head for YOLO-World compute the region-text scores according to the similarity between image and text
|
||||||
|
features.
|
||||||
|
"""
|
||||||
|
|
||||||
|
def __init__(self):
|
||||||
|
"""Initializes ContrastiveHead with specified region-text similarity parameters."""
|
||||||
|
super().__init__()
|
||||||
|
self.bias = nn.Parameter(torch.zeros([]))
|
||||||
|
self.logit_scale = nn.Parameter(torch.ones([]) * torch.tensor(1 / 0.07).log())
|
||||||
|
|
||||||
|
def forward(self, x, w):
|
||||||
|
"""Forward function of contrastive learning."""
|
||||||
|
x = F.normalize(x, dim=1, p=2)
|
||||||
|
w = F.normalize(w, dim=-1, p=2)
|
||||||
|
x = torch.einsum("bchw,bkc->bkhw", x, w)
|
||||||
|
return x * self.logit_scale.exp() + self.bias
|
||||||
|
|
||||||
|
|
||||||
|
class BNContrastiveHead(nn.Module):
|
||||||
|
"""
|
||||||
|
Batch Norm Contrastive Head for YOLO-World using batch norm instead of l2-normalization.
|
||||||
|
|
||||||
|
Args:
|
||||||
|
embed_dims (int): Embed dimensions of text and image features.
|
||||||
|
norm_cfg (dict): Normalization parameters.
|
||||||
|
"""
|
||||||
|
|
||||||
|
def __init__(self, embed_dims: int):
|
||||||
|
"""Initialize ContrastiveHead with region-text similarity parameters."""
|
||||||
|
super().__init__()
|
||||||
|
self.norm = nn.BatchNorm2d(embed_dims)
|
||||||
|
self.bias = nn.Parameter(torch.zeros([]))
|
||||||
|
# use -1.0 is more stable
|
||||||
|
self.logit_scale = nn.Parameter(-1.0 * torch.ones([]))
|
||||||
|
|
||||||
|
def forward(self, x, w):
|
||||||
|
"""Forward function of contrastive learning."""
|
||||||
|
x = self.norm(x)
|
||||||
|
w = F.normalize(w, dim=-1, p=2)
|
||||||
|
x = torch.einsum("bchw,bkc->bkhw", x, w)
|
||||||
|
return x * self.logit_scale.exp() + self.bias
|
||||||
|
|||||||
@ -8,7 +8,7 @@ import torch.nn as nn
|
|||||||
from torch.nn.init import constant_, xavier_uniform_
|
from torch.nn.init import constant_, xavier_uniform_
|
||||||
|
|
||||||
from ultralytics.utils.tal import TORCH_1_10, dist2bbox, dist2rbox, make_anchors
|
from ultralytics.utils.tal import TORCH_1_10, dist2bbox, dist2rbox, make_anchors
|
||||||
from .block import DFL, Proto
|
from .block import DFL, Proto, ContrastiveHead, BNContrastiveHead
|
||||||
from .conv import Conv
|
from .conv import Conv
|
||||||
from .transformer import MLP, DeformableTransformerDecoder, DeformableTransformerDecoderLayer
|
from .transformer import MLP, DeformableTransformerDecoder, DeformableTransformerDecoderLayer
|
||||||
from .utils import bias_init_with_prob, linear_init
|
from .utils import bias_init_with_prob, linear_init
|
||||||
@ -208,6 +208,49 @@ class Classify(nn.Module):
|
|||||||
return x if self.training else x.softmax(1)
|
return x if self.training else x.softmax(1)
|
||||||
|
|
||||||
|
|
||||||
|
class WorldDetect(Detect):
|
||||||
|
def __init__(self, nc=80, embed=512, with_bn=False, ch=()):
|
||||||
|
"""Initialize YOLOv8 detection layer with nc classes and layer channels ch."""
|
||||||
|
super().__init__(nc, ch)
|
||||||
|
c3 = max(ch[0], min(self.nc, 100))
|
||||||
|
self.cv3 = nn.ModuleList(nn.Sequential(Conv(x, c3, 3), Conv(c3, c3, 3), nn.Conv2d(c3, embed, 1)) for x in ch)
|
||||||
|
self.cv4 = nn.ModuleList(BNContrastiveHead(embed) if with_bn else ContrastiveHead() for _ in ch)
|
||||||
|
|
||||||
|
def forward(self, x, text):
|
||||||
|
"""Concatenates and returns predicted bounding boxes and class probabilities."""
|
||||||
|
for i in range(self.nl):
|
||||||
|
x[i] = torch.cat((self.cv2[i](x[i]), self.cv4[i](self.cv3[i](x[i]), text)), 1)
|
||||||
|
if self.training:
|
||||||
|
return x
|
||||||
|
|
||||||
|
# Inference path
|
||||||
|
shape = x[0].shape # BCHW
|
||||||
|
x_cat = torch.cat([xi.view(shape[0], self.nc + self.reg_max * 4, -1) for xi in x], 2)
|
||||||
|
if self.dynamic or self.shape != shape:
|
||||||
|
self.anchors, self.strides = (x.transpose(0, 1) for x in make_anchors(x, self.stride, 0.5))
|
||||||
|
self.shape = shape
|
||||||
|
|
||||||
|
if self.export and self.format in ("saved_model", "pb", "tflite", "edgetpu", "tfjs"): # avoid TF FlexSplitV ops
|
||||||
|
box = x_cat[:, : self.reg_max * 4]
|
||||||
|
cls = x_cat[:, self.reg_max * 4 :]
|
||||||
|
else:
|
||||||
|
box, cls = x_cat.split((self.reg_max * 4, self.nc), 1)
|
||||||
|
|
||||||
|
if self.export and self.format in ("tflite", "edgetpu"):
|
||||||
|
# Precompute normalization factor to increase numerical stability
|
||||||
|
# See https://github.com/ultralytics/ultralytics/issues/7371
|
||||||
|
grid_h = shape[2]
|
||||||
|
grid_w = shape[3]
|
||||||
|
grid_size = torch.tensor([grid_w, grid_h, grid_w, grid_h], device=box.device).reshape(1, 4, 1)
|
||||||
|
norm = self.strides / (self.stride[0] * grid_size)
|
||||||
|
dbox = self.decode_bboxes(self.dfl(box) * norm, self.anchors.unsqueeze(0) * norm[:, :2])
|
||||||
|
else:
|
||||||
|
dbox = self.decode_bboxes(self.dfl(box), self.anchors.unsqueeze(0)) * self.strides
|
||||||
|
|
||||||
|
y = torch.cat((dbox, cls.sigmoid()), 1)
|
||||||
|
return y if self.export else (y, x)
|
||||||
|
|
||||||
|
|
||||||
class RTDETRDecoder(nn.Module):
|
class RTDETRDecoder(nn.Module):
|
||||||
"""
|
"""
|
||||||
Real-Time Deformable Transformer Decoder (RTDETRDecoder) module for object detection.
|
Real-Time Deformable Transformer Decoder (RTDETRDecoder) module for object detection.
|
||||||
|
|||||||
@ -19,6 +19,8 @@ from ultralytics.nn.modules import (
|
|||||||
Bottleneck,
|
Bottleneck,
|
||||||
BottleneckCSP,
|
BottleneckCSP,
|
||||||
C2f,
|
C2f,
|
||||||
|
C2fAttn,
|
||||||
|
ImagePoolingAttn,
|
||||||
C3Ghost,
|
C3Ghost,
|
||||||
C3x,
|
C3x,
|
||||||
Classify,
|
Classify,
|
||||||
@ -40,6 +42,7 @@ from ultralytics.nn.modules import (
|
|||||||
ResNetLayer,
|
ResNetLayer,
|
||||||
RTDETRDecoder,
|
RTDETRDecoder,
|
||||||
Segment,
|
Segment,
|
||||||
|
WorldDetect,
|
||||||
)
|
)
|
||||||
from ultralytics.utils import DEFAULT_CFG_DICT, DEFAULT_CFG_KEYS, LOGGER, colorstr, emojis, yaml_load
|
from ultralytics.utils import DEFAULT_CFG_DICT, DEFAULT_CFG_KEYS, LOGGER, colorstr, emojis, yaml_load
|
||||||
from ultralytics.utils.checks import check_requirements, check_suffix, check_yaml
|
from ultralytics.utils.checks import check_requirements, check_suffix, check_yaml
|
||||||
@ -222,7 +225,7 @@ class BaseModel(nn.Module):
|
|||||||
"""
|
"""
|
||||||
self = super()._apply(fn)
|
self = super()._apply(fn)
|
||||||
m = self.model[-1] # Detect()
|
m = self.model[-1] # Detect()
|
||||||
if isinstance(m, (Detect, Segment)):
|
if isinstance(m, Detect): # includes all Detect subclasses like Segment, Pose, OBB, WorldDetect
|
||||||
m.stride = fn(m.stride)
|
m.stride = fn(m.stride)
|
||||||
m.anchors = fn(m.anchors)
|
m.anchors = fn(m.anchors)
|
||||||
m.strides = fn(m.strides)
|
m.strides = fn(m.strides)
|
||||||
@ -281,7 +284,7 @@ class DetectionModel(BaseModel):
|
|||||||
|
|
||||||
# Build strides
|
# Build strides
|
||||||
m = self.model[-1] # Detect()
|
m = self.model[-1] # Detect()
|
||||||
if isinstance(m, (Detect, Segment, Pose, OBB)):
|
if isinstance(m, Detect): # includes all Detect subclasses like Segment, Pose, OBB, WorldDetect
|
||||||
s = 256 # 2x min stride
|
s = 256 # 2x min stride
|
||||||
m.inplace = self.inplace
|
m.inplace = self.inplace
|
||||||
forward = lambda x: self.forward(x)[0] if isinstance(m, (Segment, Pose, OBB)) else self.forward(x)
|
forward = lambda x: self.forward(x)[0] if isinstance(m, (Segment, Pose, OBB)) else self.forward(x)
|
||||||
@ -546,6 +549,77 @@ class RTDETRDetectionModel(DetectionModel):
|
|||||||
return x
|
return x
|
||||||
|
|
||||||
|
|
||||||
|
class WorldModel(DetectionModel):
|
||||||
|
"""YOLOv8 World Model."""
|
||||||
|
|
||||||
|
def __init__(self, cfg="yolov8s-world.yaml", ch=3, nc=None, verbose=True):
|
||||||
|
"""Initialize YOLOv8 world model with given config and parameters."""
|
||||||
|
self.txt_feats = torch.randn(1, nc or 80, 512) # placeholder
|
||||||
|
super().__init__(cfg=cfg, ch=ch, nc=nc, verbose=verbose)
|
||||||
|
|
||||||
|
def set_classes(self, text):
|
||||||
|
"""Perform a forward pass with optional profiling, visualization, and embedding extraction."""
|
||||||
|
try:
|
||||||
|
import clip
|
||||||
|
except ImportError:
|
||||||
|
check_requirements("git+https://github.com/openai/CLIP.git")
|
||||||
|
import clip
|
||||||
|
|
||||||
|
model, _ = clip.load("ViT-B/32")
|
||||||
|
device = next(model.parameters()).device
|
||||||
|
text_token = clip.tokenize(text).to(device)
|
||||||
|
txt_feats = model.encode_text(text_token).to(dtype=torch.float32)
|
||||||
|
txt_feats = txt_feats / txt_feats.norm(p=2, dim=-1, keepdim=True)
|
||||||
|
self.txt_feats = txt_feats.reshape(-1, len(text), txt_feats.shape[-1])
|
||||||
|
self.model[-1].nc = len(text)
|
||||||
|
|
||||||
|
def init_criterion(self):
|
||||||
|
"""Initialize the loss criterion for the model."""
|
||||||
|
raise NotImplementedError
|
||||||
|
|
||||||
|
def predict(self, x, profile=False, visualize=False, augment=False, embed=None):
|
||||||
|
"""
|
||||||
|
Perform a forward pass through the model.
|
||||||
|
|
||||||
|
Args:
|
||||||
|
x (torch.Tensor): The input tensor.
|
||||||
|
profile (bool, optional): If True, profile the computation time for each layer. Defaults to False.
|
||||||
|
visualize (bool, optional): If True, save feature maps for visualization. Defaults to False.
|
||||||
|
augment (bool, optional): If True, perform data augmentation during inference. Defaults to False.
|
||||||
|
embed (list, optional): A list of feature vectors/embeddings to return.
|
||||||
|
|
||||||
|
Returns:
|
||||||
|
(torch.Tensor): Model's output tensor.
|
||||||
|
"""
|
||||||
|
txt_feats = self.txt_feats.to(device=x.device, dtype=x.dtype)
|
||||||
|
if len(txt_feats) != len(x):
|
||||||
|
txt_feats = txt_feats.repeat(len(x), 1, 1)
|
||||||
|
ori_txt_feats = txt_feats.clone()
|
||||||
|
y, dt, embeddings = [], [], [] # outputs
|
||||||
|
for m in self.model: # except the head part
|
||||||
|
if m.f != -1: # if not from previous layer
|
||||||
|
x = y[m.f] if isinstance(m.f, int) else [x if j == -1 else y[j] for j in m.f] # from earlier layers
|
||||||
|
if profile:
|
||||||
|
self._profile_one_layer(m, x, dt)
|
||||||
|
if isinstance(m, C2fAttn):
|
||||||
|
x = m(x, txt_feats)
|
||||||
|
elif isinstance(m, WorldDetect):
|
||||||
|
x = m(x, ori_txt_feats)
|
||||||
|
elif isinstance(m, ImagePoolingAttn):
|
||||||
|
txt_feats = m(x, txt_feats)
|
||||||
|
else:
|
||||||
|
x = m(x) # run
|
||||||
|
|
||||||
|
y.append(x if m.i in self.save else None) # save output
|
||||||
|
if visualize:
|
||||||
|
feature_visualization(x, m.type, m.i, save_dir=visualize)
|
||||||
|
if embed and m.i in embed:
|
||||||
|
embeddings.append(nn.functional.adaptive_avg_pool2d(x, (1, 1)).squeeze(-1).squeeze(-1)) # flatten
|
||||||
|
if m.i == max(embed):
|
||||||
|
return torch.unbind(torch.cat(embeddings, 1), dim=0)
|
||||||
|
return x
|
||||||
|
|
||||||
|
|
||||||
class Ensemble(nn.ModuleList):
|
class Ensemble(nn.ModuleList):
|
||||||
"""Ensemble of models."""
|
"""Ensemble of models."""
|
||||||
|
|
||||||
@ -685,11 +759,8 @@ def attempt_load_weights(weights, device=None, inplace=True, fuse=False):
|
|||||||
|
|
||||||
# Module updates
|
# Module updates
|
||||||
for m in ensemble.modules():
|
for m in ensemble.modules():
|
||||||
t = type(m)
|
if hasattr(m, "inplace"):
|
||||||
if t in (nn.Hardswish, nn.LeakyReLU, nn.ReLU, nn.ReLU6, nn.SiLU, Detect, Segment, Pose, OBB):
|
|
||||||
m.inplace = inplace
|
m.inplace = inplace
|
||||||
elif t is nn.Upsample and not hasattr(m, "recompute_scale_factor"):
|
|
||||||
m.recompute_scale_factor = None # torch 1.11.0 compatibility
|
|
||||||
|
|
||||||
# Return model
|
# Return model
|
||||||
if len(ensemble) == 1:
|
if len(ensemble) == 1:
|
||||||
@ -699,7 +770,7 @@ def attempt_load_weights(weights, device=None, inplace=True, fuse=False):
|
|||||||
LOGGER.info(f"Ensemble created with {weights}\n")
|
LOGGER.info(f"Ensemble created with {weights}\n")
|
||||||
for k in "names", "nc", "yaml":
|
for k in "names", "nc", "yaml":
|
||||||
setattr(ensemble, k, getattr(ensemble[0], k))
|
setattr(ensemble, k, getattr(ensemble[0], k))
|
||||||
ensemble.stride = ensemble[torch.argmax(torch.tensor([m.stride.max() for m in ensemble])).int()].stride
|
ensemble.stride = ensemble[int(torch.argmax(torch.tensor([m.stride.max() for m in ensemble])))].stride
|
||||||
assert all(ensemble[0].nc == m.nc for m in ensemble), f"Models differ in class counts {[m.nc for m in ensemble]}"
|
assert all(ensemble[0].nc == m.nc for m in ensemble), f"Models differ in class counts {[m.nc for m in ensemble]}"
|
||||||
return ensemble
|
return ensemble
|
||||||
|
|
||||||
@ -721,11 +792,8 @@ def attempt_load_one_weight(weight, device=None, inplace=True, fuse=False):
|
|||||||
|
|
||||||
# Module updates
|
# Module updates
|
||||||
for m in model.modules():
|
for m in model.modules():
|
||||||
t = type(m)
|
if hasattr(m, "inplace"):
|
||||||
if t in (nn.Hardswish, nn.LeakyReLU, nn.ReLU, nn.ReLU6, nn.SiLU, Detect, Segment, Pose, OBB):
|
|
||||||
m.inplace = inplace
|
m.inplace = inplace
|
||||||
elif t is nn.Upsample and not hasattr(m, "recompute_scale_factor"):
|
|
||||||
m.recompute_scale_factor = None # torch 1.11.0 compatibility
|
|
||||||
|
|
||||||
# Return model and ckpt
|
# Return model and ckpt
|
||||||
return model, ckpt
|
return model, ckpt
|
||||||
@ -778,6 +846,7 @@ def parse_model(d, ch, verbose=True): # model_dict, input_channels(3)
|
|||||||
C1,
|
C1,
|
||||||
C2,
|
C2,
|
||||||
C2f,
|
C2f,
|
||||||
|
C2fAttn,
|
||||||
C3,
|
C3,
|
||||||
C3TR,
|
C3TR,
|
||||||
C3Ghost,
|
C3Ghost,
|
||||||
@ -789,9 +858,14 @@ def parse_model(d, ch, verbose=True): # model_dict, input_channels(3)
|
|||||||
c1, c2 = ch[f], args[0]
|
c1, c2 = ch[f], args[0]
|
||||||
if c2 != nc: # if c2 not equal to number of classes (i.e. for Classify() output)
|
if c2 != nc: # if c2 not equal to number of classes (i.e. for Classify() output)
|
||||||
c2 = make_divisible(min(c2, max_channels) * width, 8)
|
c2 = make_divisible(min(c2, max_channels) * width, 8)
|
||||||
|
if m is C2fAttn:
|
||||||
|
args[1] = make_divisible(min(args[1], max_channels // 2) * width, 8) # embed channels
|
||||||
|
args[2] = int(
|
||||||
|
max(round(min(args[2], max_channels // 2 // 32)) * width, 1) if args[2] > 1 else args[2]
|
||||||
|
) # num heads
|
||||||
|
|
||||||
args = [c1, c2, *args[1:]]
|
args = [c1, c2, *args[1:]]
|
||||||
if m in (BottleneckCSP, C1, C2, C2f, C3, C3TR, C3Ghost, C3x, RepC3):
|
if m in (BottleneckCSP, C1, C2, C2f, C2fAttn, C3, C3TR, C3Ghost, C3x, RepC3):
|
||||||
args.insert(2, n) # number of repeats
|
args.insert(2, n) # number of repeats
|
||||||
n = 1
|
n = 1
|
||||||
elif m is AIFI:
|
elif m is AIFI:
|
||||||
@ -808,7 +882,7 @@ def parse_model(d, ch, verbose=True): # model_dict, input_channels(3)
|
|||||||
args = [ch[f]]
|
args = [ch[f]]
|
||||||
elif m is Concat:
|
elif m is Concat:
|
||||||
c2 = sum(ch[x] for x in f)
|
c2 = sum(ch[x] for x in f)
|
||||||
elif m in (Detect, Segment, Pose, OBB):
|
elif m in (Detect, WorldDetect, Segment, Pose, OBB, ImagePoolingAttn):
|
||||||
args.append([ch[x] for x in f])
|
args.append([ch[x] for x in f])
|
||||||
if m is Segment:
|
if m is Segment:
|
||||||
args[2] = make_divisible(min(args[2], max_channels) * width, 8)
|
args[2] = make_divisible(min(args[2], max_channels) * width, 8)
|
||||||
@ -911,9 +985,7 @@ def guess_model_task(model):
|
|||||||
return cfg2task(eval(x))
|
return cfg2task(eval(x))
|
||||||
|
|
||||||
for m in model.modules():
|
for m in model.modules():
|
||||||
if isinstance(m, Detect):
|
if isinstance(m, Segment):
|
||||||
return "detect"
|
|
||||||
elif isinstance(m, Segment):
|
|
||||||
return "segment"
|
return "segment"
|
||||||
elif isinstance(m, Classify):
|
elif isinstance(m, Classify):
|
||||||
return "classify"
|
return "classify"
|
||||||
@ -921,6 +993,8 @@ def guess_model_task(model):
|
|||||||
return "pose"
|
return "pose"
|
||||||
elif isinstance(m, OBB):
|
elif isinstance(m, OBB):
|
||||||
return "obb"
|
return "obb"
|
||||||
|
elif isinstance(m, (Detect, WorldDetect)):
|
||||||
|
return "detect"
|
||||||
|
|
||||||
# Guess from model filename
|
# Guess from model filename
|
||||||
if isinstance(model, (str, Path)):
|
if isinstance(model, (str, Path)):
|
||||||
|
|||||||
@ -783,6 +783,7 @@ class Retry(contextlib.ContextDecorator):
|
|||||||
"""Decorator implementation for Retry with exponential backoff."""
|
"""Decorator implementation for Retry with exponential backoff."""
|
||||||
|
|
||||||
def wrapped_func(*args, **kwargs):
|
def wrapped_func(*args, **kwargs):
|
||||||
|
"""Applies retries to the decorated function or method."""
|
||||||
self._attempts = 0
|
self._attempts = 0
|
||||||
while self._attempts < self.times:
|
while self._attempts < self.times:
|
||||||
try:
|
try:
|
||||||
|
|||||||
@ -20,6 +20,7 @@ GITHUB_ASSETS_NAMES = (
|
|||||||
[f"yolov8{k}{suffix}.pt" for k in "nsmlx" for suffix in ("", "-cls", "-seg", "-pose", "-obb")]
|
[f"yolov8{k}{suffix}.pt" for k in "nsmlx" for suffix in ("", "-cls", "-seg", "-pose", "-obb")]
|
||||||
+ [f"yolov5{k}{resolution}u.pt" for k in "nsmlx" for resolution in ("", "6")]
|
+ [f"yolov5{k}{resolution}u.pt" for k in "nsmlx" for resolution in ("", "6")]
|
||||||
+ [f"yolov3{k}u.pt" for k in ("", "-spp", "-tiny")]
|
+ [f"yolov3{k}u.pt" for k in ("", "-spp", "-tiny")]
|
||||||
|
+ [f"yolov8{k}-world.pt" for k in "sml"]
|
||||||
+ [f"yolo_nas_{k}.pt" for k in "sml"]
|
+ [f"yolo_nas_{k}.pt" for k in "sml"]
|
||||||
+ [f"sam_{k}.pt" for k in "bl"]
|
+ [f"sam_{k}.pt" for k in "bl"]
|
||||||
+ [f"FastSAM-{k}.pt" for k in "sx"]
|
+ [f"FastSAM-{k}.pt" for k in "sx"]
|
||||||
|
|||||||
@ -250,7 +250,8 @@ class Annotator:
|
|||||||
kpt_line (bool, optional): If True, the function will draw lines connecting keypoints
|
kpt_line (bool, optional): If True, the function will draw lines connecting keypoints
|
||||||
for human pose. Default is True.
|
for human pose. Default is True.
|
||||||
|
|
||||||
Note: `kpt_line=True` currently only supports human pose plotting.
|
Note:
|
||||||
|
`kpt_line=True` currently only supports human pose plotting.
|
||||||
"""
|
"""
|
||||||
if self.pil:
|
if self.pil:
|
||||||
# Convert to numpy first
|
# Convert to numpy first
|
||||||
|
|||||||
Loading…
x
Reference in New Issue
Block a user